
1M+
Trajectories
21
Robot Embodiments
140,000+
Trajs. from Mixed Expertise Datasets







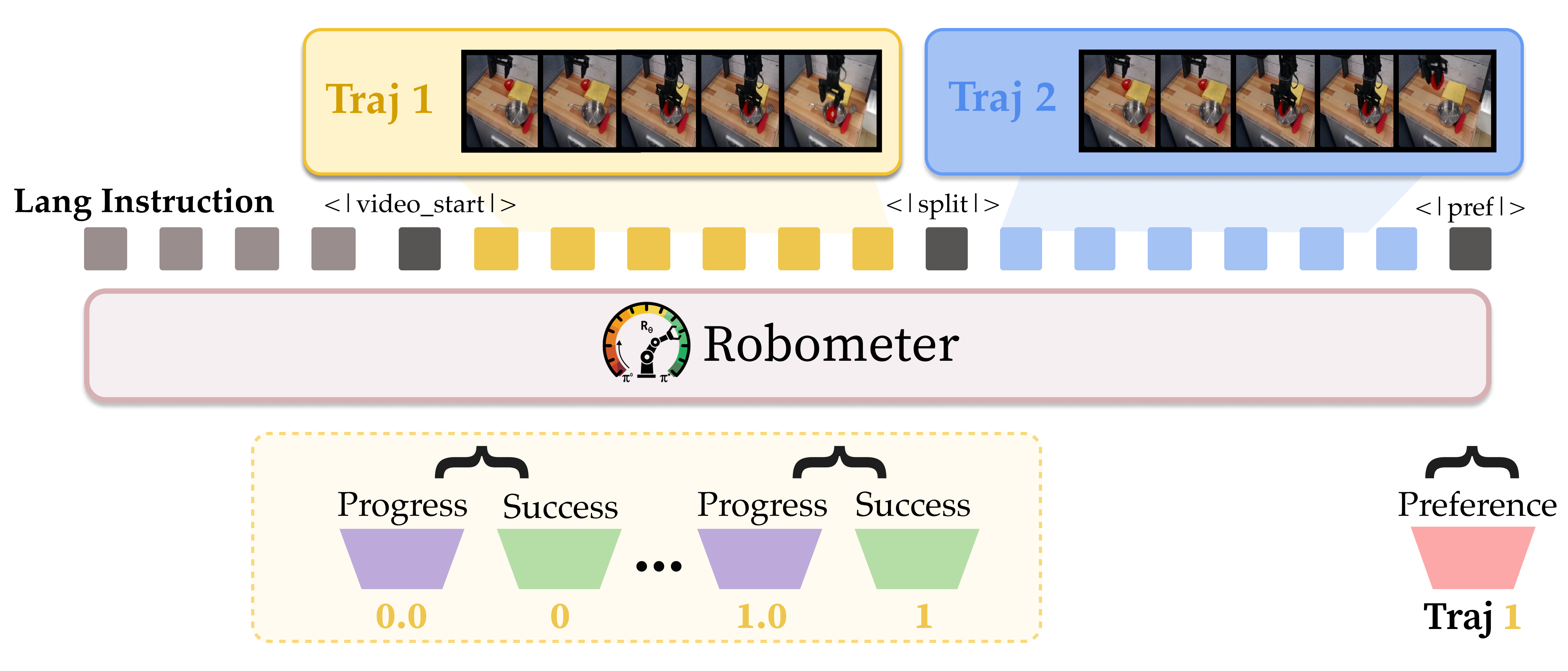
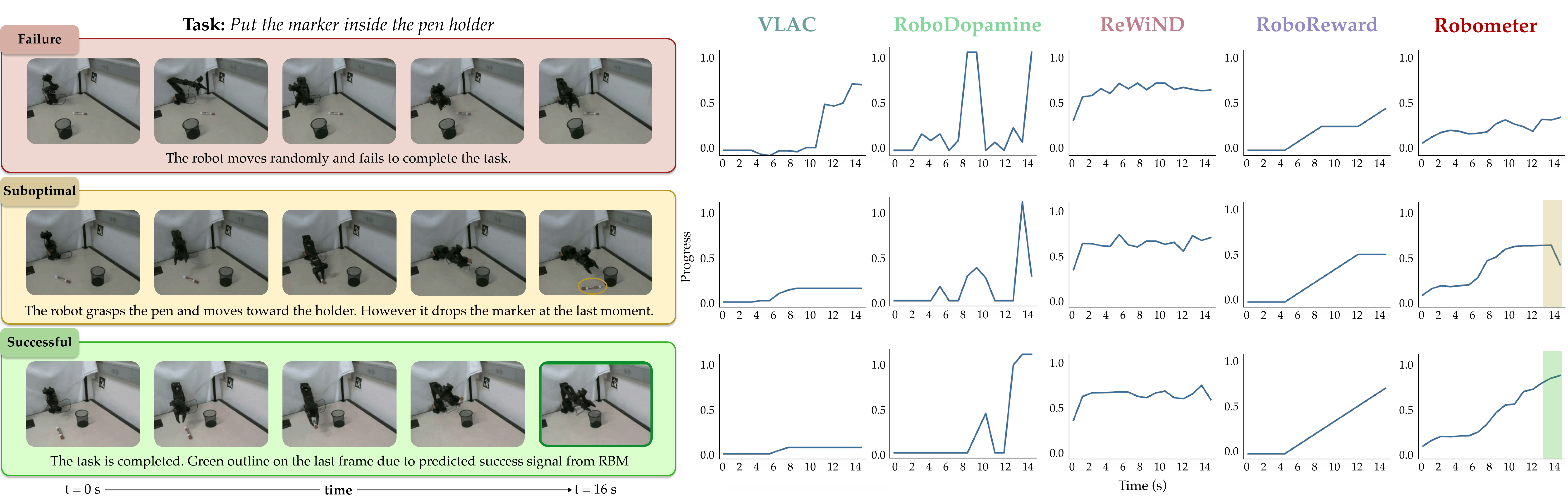
Reward curves predicted by Robometer and ablated variants on example trajectories.
| Dataset | Baselines | w/ RoboReward Training Data | w/ our RBM-1M data | |||||
|---|---|---|---|---|---|---|---|---|
| GVL | VLAC | RoboDopamine | RoboReward-4B | RoboReward-8B | Robometer | ReWiND | Robometer | |
| (a) Reward alignment (VOC Pearson $r$) ↑ | ||||||||
| RBM-EVAL-ID | 0.16 | 0.16 | 0.13 | 0.77 | 0.82 | 0.84 | 0.46 | 0.92 |
| RBM-EVAL-OOD | 0.21 | 0.17 | 0.08 | 0.88 | 0.88 | 0.93 | 0.51 | 0.95 |
| (b) Trajectory ranking (Kendall $\tau$) ↑ | ||||||||
| RBM-EVAL-OOD | 0.19 | 0.08 | 0.11 | 0.50 | 0.47 | 0.55 | 0.01 | 0.66 |
(a) Reward alignment (VOC Pearson $r$) and (b) trajectory ranking (Kendall $\tau_a$) on RBM-EVAL. Baselines by training data: GVL (w/ GPT-5-mini, unknown data), VLAC (300k trajectories), RoboDopamine (100k). We compare Robometer to RoboReward-4B/8B on their data, and ReWiND and Robometer on the full RBM-1M dataset.
| Model Type | Model | RoboRewardBench MAE ↓ |
|---|---|---|
| Qwen3-4B Models | Robometer (ours) | 0.72 |
| Robometer (RoboReward data only) | 0.75 | |
| RoboReward-4B | 0.85 | |
| Qwen3-VL-4B-Instr. | 1.03 |
Evaluation on the RoboRewardBench benchmark (mean absolute error, lower is better).
Different Quality
| Dataset | RL-VLM-F (%) | Robometer (%) |
|---|---|---|
| USC Franka | 52.1 | 75.0 |
| USC Koch | 54.4 | 79.4 |
| USC Trossen | 66.7 | 76.2 |
| USC xArm | 48.6 | 88.9 |
| MIT Franka | 54.4 | 85.4 |
| UT Dallas SO-101 | 56.7 | 90.0 |
| Average | 55.5 | 82.5 |
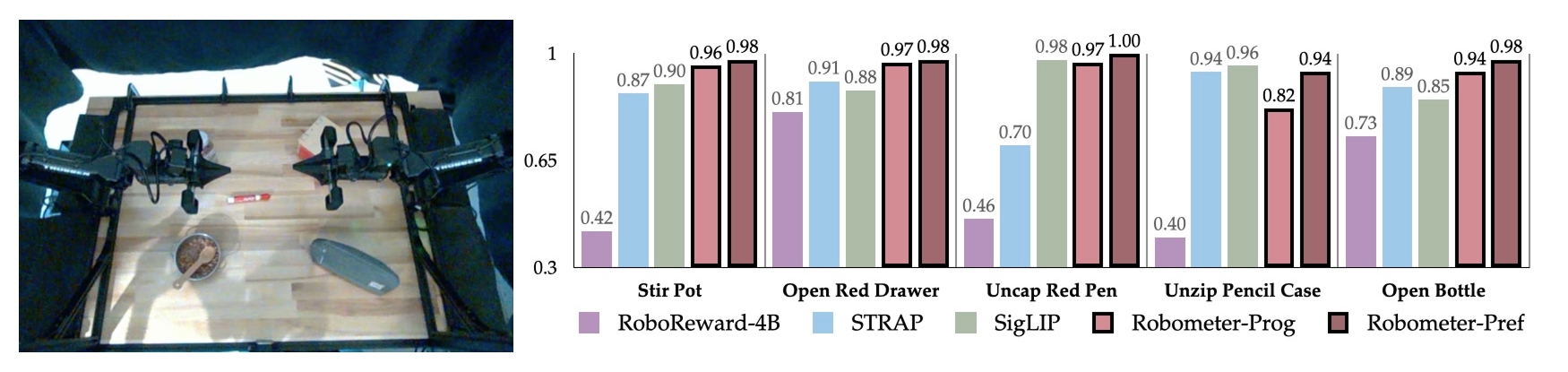
Different quality trajectory pairwise preference accuracy.
Different task
| Dataset | RL-VLM-F (%) | Robometer (%) |
|---|---|---|
| USC Franka | 70.7 | 100.0 |
| USC Koch | 54.7 | 89.8 |
| USC Trossen | 64.0 | 99.0 |
| USC xArm | 73.3 | 98.2 |
| MIT Franka | 55.3 | 98.4 |
| UT Dallas SO-101 | 72.7 | 100.0 |
| Average | 65.1 | 97.6 |
Different task trajectory pairwise preference accuracy.
Select a task to view the reward curve video.
Robometer is evaluated across five diverse downstream applications. In every setting Robometer is used as a plug-in reward function without task-specific fine-tuning.
| Method | Success Rate ↑ |
|---|---|
| $\pi_0$ base (before RL) | 0.20 |
| RoboReward | 0.55 |
| Robometer (ours) ✓ | 0.85 |
| Method | Success Rate ↑ |
|---|---|
| $\pi_0$ base (before RL) | 0.20 |
| RoboReward | 0.20 |
| Robometer (ours) ✓ | 0.70 |
Try the reward model evaluation UI below, or separate visit in a new tab at https://robometer-rewardeval-ui.hf.space.
Robometer serves as a strong initialization for domain-specific reward fine-tuning: practitioners can adapt it to new tasks or embodiments with limited data and compute (e.g., LoRA with a single GPU) instead of training a reward model from scratch. We demonstrate this on RoboFAC; fine-tuning from Robometer substantially outperforms fine-tuning the base VLM across reward and ranking metrics.
| Method | VOC $r$ ↑ | Kendall $\tau$ ↑ | Succ-Fail Diff ↑ |
|---|---|---|---|
| Robometer-4B (Zero-shot) | 0.652 | 0.436 | 0.141 |
| Qwen3-VL (LoRA) | 0.701 | 0.067 | 0.005 |
| Qwen3-VL (Full FT) | 0.727 | 0.102 | 0.008 |
| Robometer-4B (LoRA) | 0.875 | 0.786 | 0.271 |
| Robometer-4B (Full FT) | 0.884 | 0.802 | 0.302 |